


Embeddings & Vector Space // BrXnd Dispatch vol. 017
Embeddings & Vector Space // BrXnd Dispatch vol. 017
In which I do my best to explain multi-dimensional vector space as simply as possible.

You’re getting this email as a subscriber to the BrXnd Dispatch, a (roughly) bi-weekly email at the intersection of brands and AI. On May 16th, we’re holding the BrXnd Marketing X AI Conference. Tickets have gone much faster than expected, and the waitlist is now open. I fully expect to release more tickets, but until I can better grasp all the sponsor and speaker requirements, it’s safest to do it this way. Add your name to the waitlist to be immediately informed when more tickets are available. With that said, sponsor tickets are still available, so if you’d like to sponsor the event, please be in touch.
Hello everyone, and welcome to another Dispatch. I’m away with the family this week, but I wanted to keep the content flowing.
Last week I went down to BrandCenter at VCU to give a talk about some of the experiments I have been building at the intersection of brands and AI. Specifically, I talked about how I’ve been going about trying to gain intuition through building. I spoke about my CollXbs project, some new bot work I’ve been playing with (building hybrid synthetic/qualitative research bots), and lots about embeddings, using my work on the Marketing AI landscape as the jumping-off point.
If you haven’t played with the BrXndscape Marketing AI Landscape, go have a look. Specifically, try out the use case search, where you can type in anything you want to accomplish with Marketing AI and see which categories and tools are the best match.

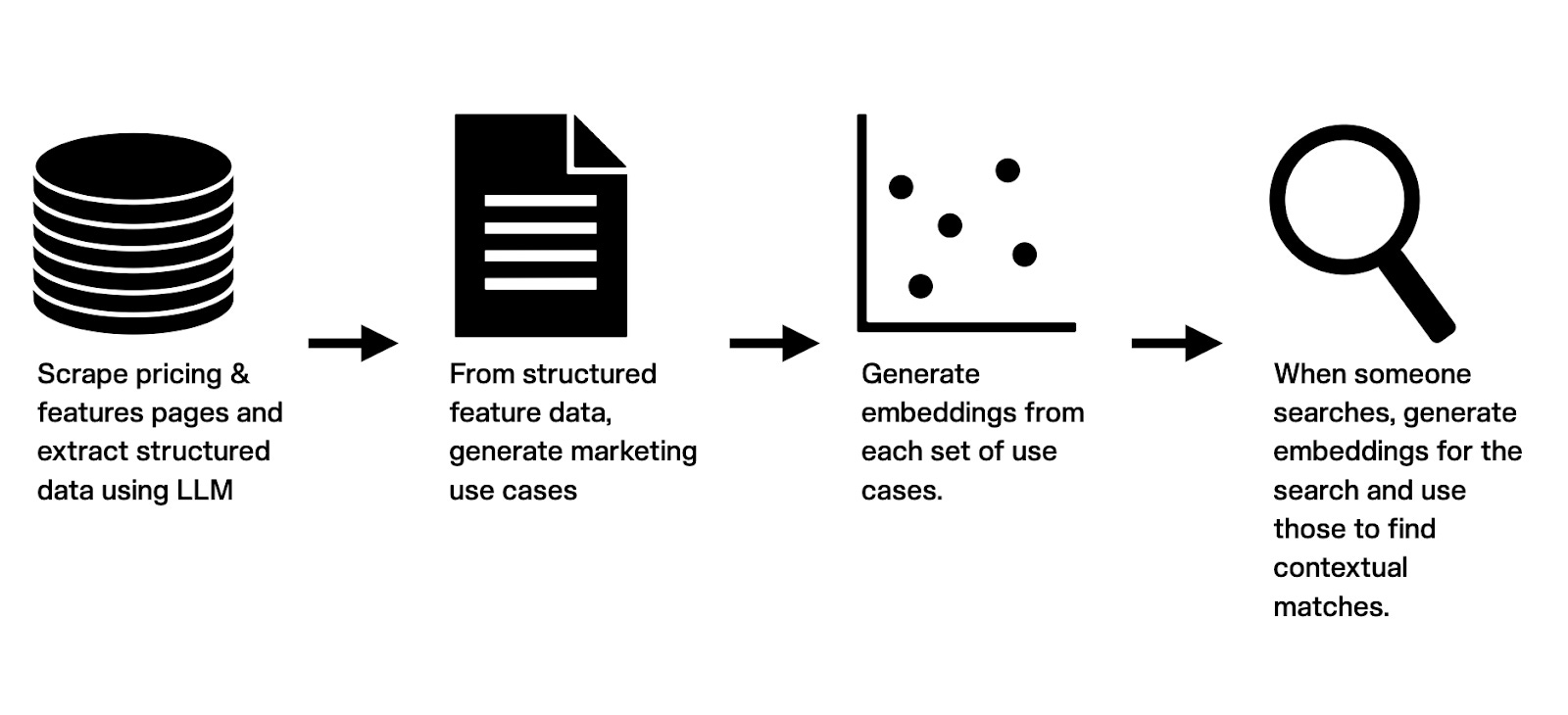
What’s going on behind the scenes there is pretty neat and one of those aha moments for me as I was able to do something I had never been able to do before. In its most simplified form, the process is that for each company added to the landscape, I scrape their product page, parse its features, and then generate a set of use cases for marketers. Those use cases look something like this: “Reduce time spent on email management Increase customer satisfaction by providing timely and accurate responses Unlock untapped information within the company.” They’re generated by a fine-tuned model set up to take the features and determine what marketers could do with them. It works pretty well.
From there, though, the magic really starts to happen. Using another OpenAI product called embeddings, I’m able to grab a set of 1,536 numbers for the set of use cases that represents their location in multi-dimensional vector space (I’ll explain this in a second). The whole process looks something like this:
Multi-Dimensional Vector Space?
Right. That’s where people get stuck. But for all the talk about ChatGPT and text completion, the underlying embeddings may be an even more immediately useful tool for enterprises. That’s because embeddings allow you to automatically take any data and locate it contextually in space. That means you feed it a bunch of use cases, for instance, and it will naturally cluster the relevant ones together. It’s amazing, but let me try to explain this multi-dimensional vector space thing a bit better.
Let’s start super simple with one dimension. In this case, it’s a line that goes from fish to bird (the students at VCU informed me that a whale is not, in fact, a fish … but for the purposes of this explanation, please just play along).

If we have a line from fish to bird, it’s pretty easy to figure out that the killer whale goes on the left, and the penguin on the right. But what happens if we add a flamingo?

That’s no problem. We would just put it over the penguin. But a flamingo and a penguin are obviously different animals, so ideally, we add another dimension to differentiate. No problem, let’s just put in a y-axis for color.

Solved. Everyone has their own place, and we are all good. Our x-axis is the animal type, and our y-axis is the color. But where do we put a pink parrot?

Now we need another dimension. Unfortunately, going from two- to three-dimensional space in Keynote isn’t the best, so bear with me as I do my best designer impression.
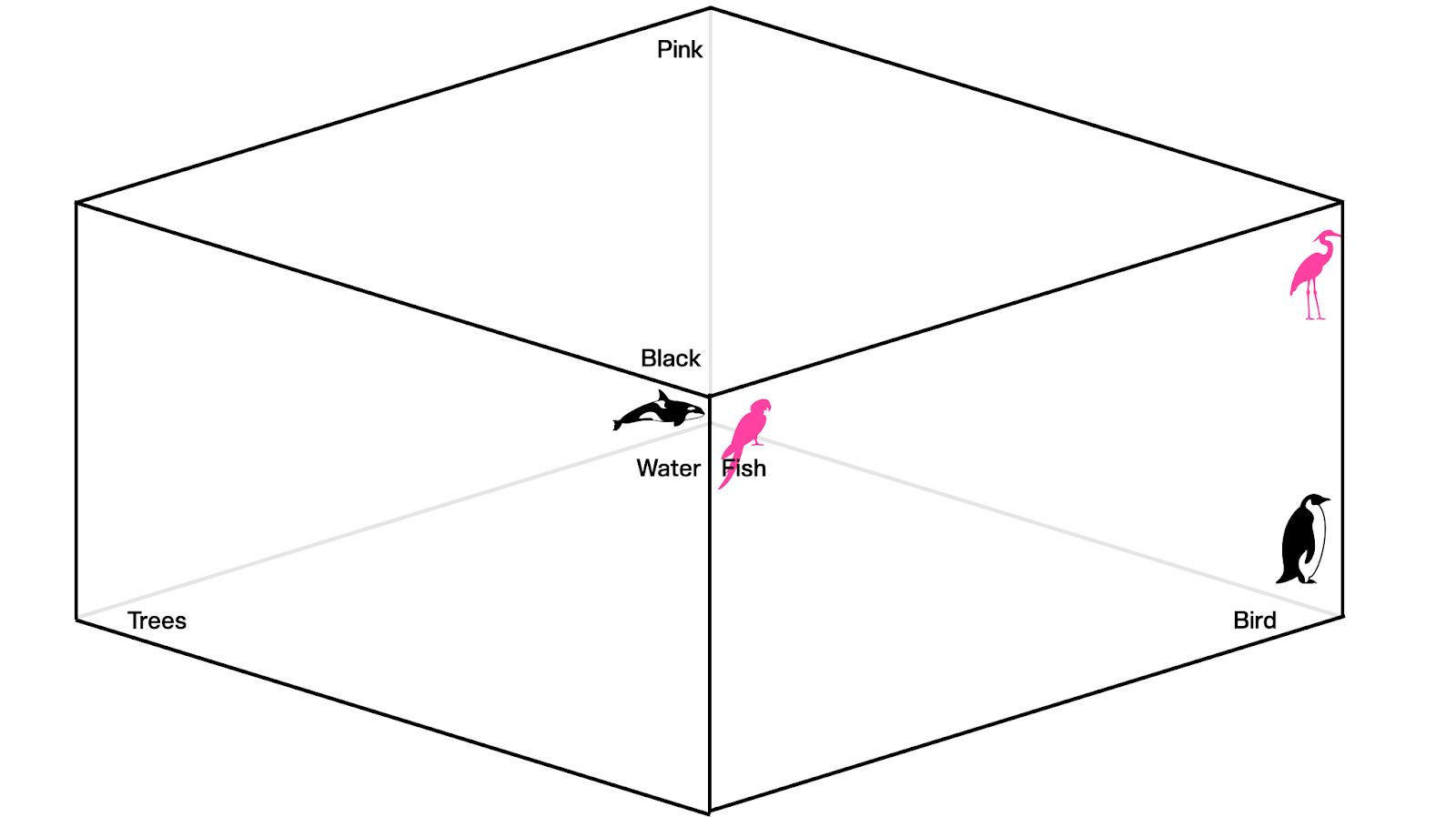
I’ve added a third dimension, in this case, one that represents whether the animal lives in water or trees, to differentiate between our pink parrot and our pink flamingo. Obviously, all this is super simplified, but the basic idea is that each dimension represents an attribute, and you can start to map all things in this multidimensional space. If we added a pink and black tree bird, for instance, it would become the nearest neighbor of our parrot. As we add more animals, clusters of similar animals will emerge, allowing us to navigate around this space.
BRXND SPONSORS
A huge thank you to the many supportive sponsors who are making the event and my work possible. If you would like to sponsor, please be in touch.

Let me bring us back to reality and do a super simplified version of what’s happening with the landscape. If you were to search for something like “I want to write better blog posts,” the first thing that happens is I go grab the vector coordinates that represent that search in vector space according to the AI’s contextual understanding. For explanatory purposes, let’s assume it’s located at .2 on the x-axis, .2 on the y-axis in this hyper-simplified two-dimensional space (again, the actual embeddings from OpenAI I’m using are 1,536-dimensional space).
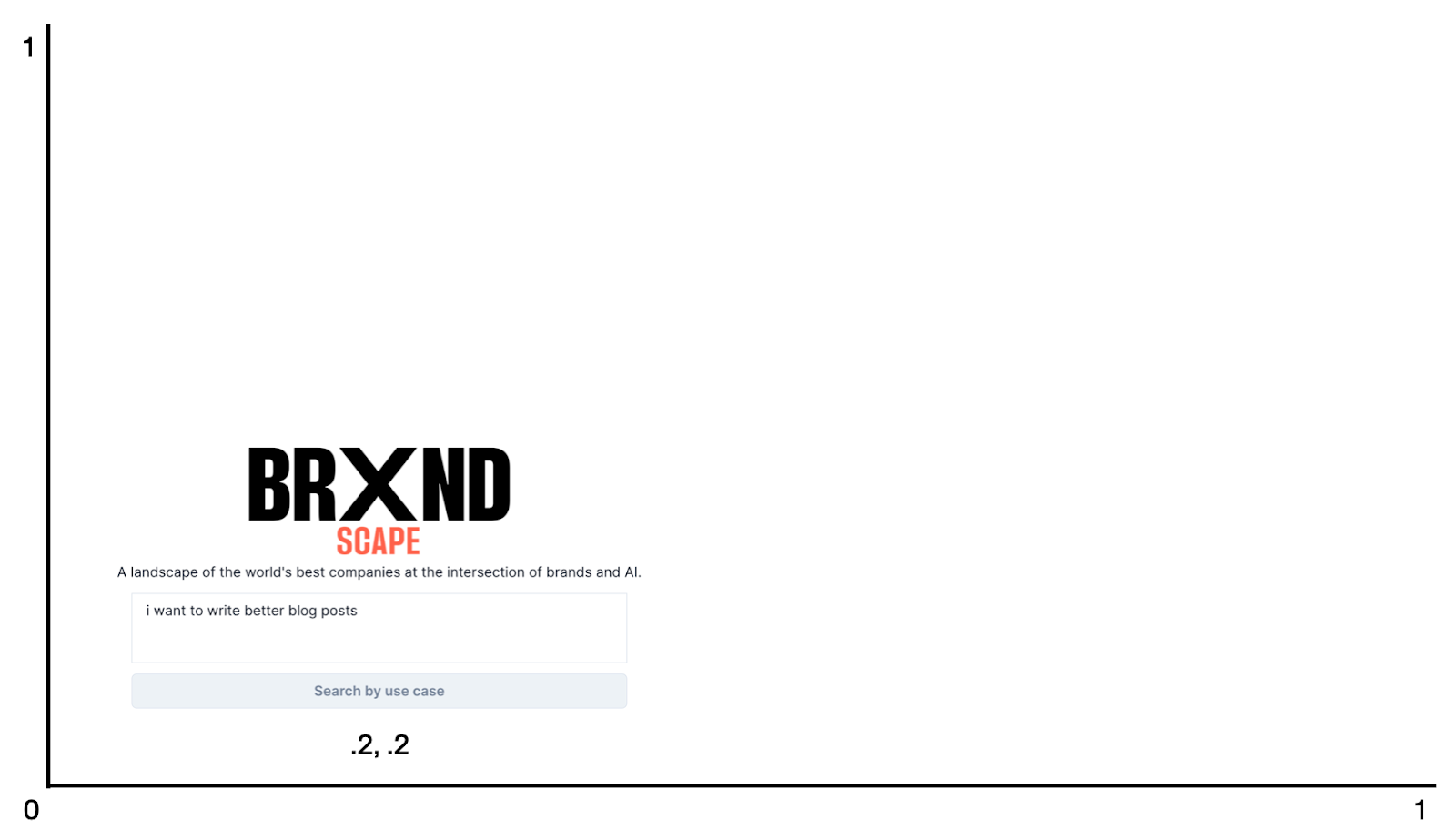
Now, using a vector database called Pinecone, which does most of the work of storing and searching vector space. I grab all the categories that are the closest matches to .2, .2. Again, for illustrative purposes, it looks something like this:
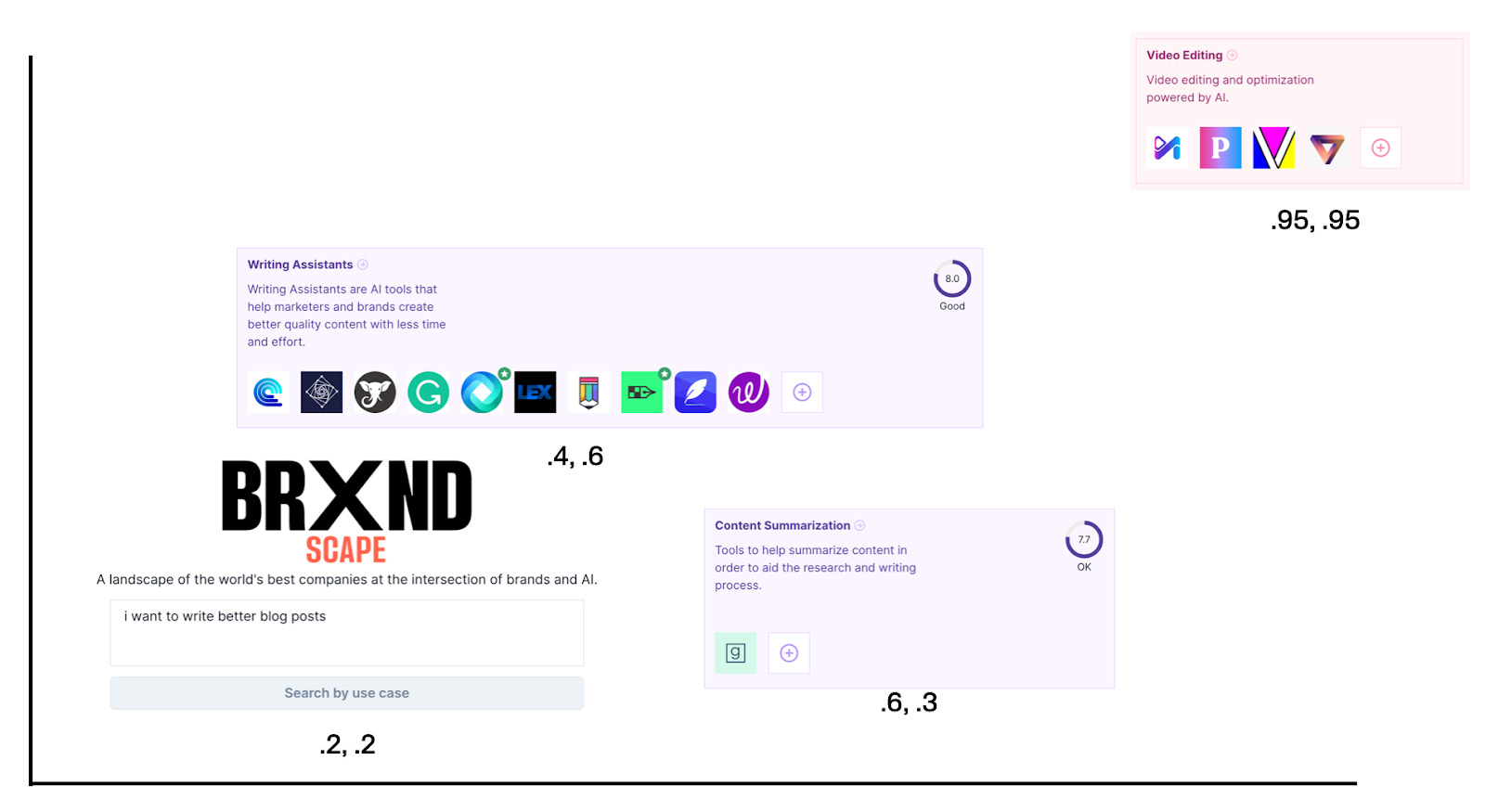
Writing assistants and content summarization are the closest categories to our search, while video editing is about as far away as possible. Therefore, it returns those categories as strong matches when you ask it the question.
A few things I think are particularly interesting about all this:
It’s all possible because the large language model has built up a contextual “understanding” of language. That’s what makes the embeddings so good.
The metaphor of vector space is one I find particularly useful. There are a lot of problems that look like this inside organizations. For instance, inside big agencies or consultancies, you are constantly trying to find the best people to work on a particular brief or project. That’s essentially a vector space problem: rather than what we do right now, where we look for experiences using a taxonomy of categories or some other method, it would likely be much more useful to be able to contextually search a vector space of all employees to match them to projects. (It’s possible big consultancies already do this, if so, I’d love to hear about it).
Another place where this is a no-brainer is searching documentation. Whether it’s internal documentation like employee handbooks or customer-facing documentation for your product, adding a natural language search layer over it makes tons of sense. Supabase, which I use a lot and love (it’s how I run the Landscape), recently implemented AI over their docs to let you ask questions, and it’s awesome.

Most of all, though, what’s most impressive is how easy it is to do right now. I got Landscape search running this way in something like an hour. That was a completely mind-blowing experience. The speed and cost of generating embeddings are amazing (storage and retrieval are a bit more expensive), and it doesn’t come with the same kind of legal baggage as some of the other more outward-facing generative AI stuff. While I realize most of you have no plans to write code, I believe that having a mental model for how this stuff works is critically important and helpful.
Let me know if you have any questions.
And, of course, see you in May at the BrXnd Marketing AI Conference! It’s coming up fast.
— Noah
PS - If you haven’t joined the BrXnd.ai Discord yet and want to talk with other marketers about AI, come on over.